GraphAttack+MAPLE: Optimizing Data Supply for Graph Applications on In-Order Multicore Architectures
Abstract
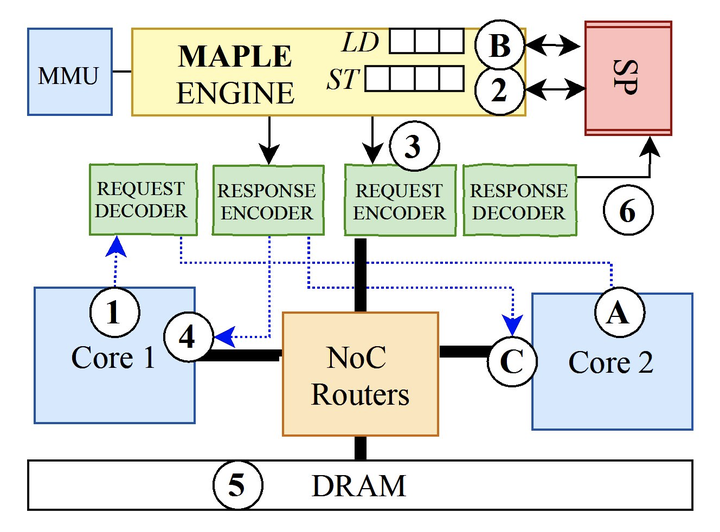
Graph structures are a natural representation for data generated by a wide range of sources. While graph applications have significant parallelism, their pointer indirect accesses to neighbor data hinder scalability. A scalable and efficient system must tolerate latency while leveraging data parallelism across millions of vertices. Existing solutions have shortcomings; modern OoO cores are area- and energy-inefficient, while specialized accelerator and memory hierarchy designs cannot support diverse application demands.In this talk we will describe a full-stack data supply approach, GraphAttack, that accelerates graph applications on in-order multi-core architectures by mitigating latency bottlenecks. GraphAttack’s compiler identifies long-latency loads and slices programs along these loads into Producer/Consumer threads to map onto pairs of parallel cores. A specialized hardware unit shared by each core pair, called Memory Access Parallel-Load Engine (MAPLE), allows tracking and buffering of asynchronous loads issued by the Producer whose data are used by the Consumer. In equal-area comparisons via simulation, GraphAttack outperforms OoO cores, do-all parallelism, prefetching, and prior decoupling approaches, achieving a 2.87x speedup and 8.61x gain in energy efficiency across a range of graph applications. These improvements scale; GraphAttack achieves a 3x speedup over 64 parallel cores. Our approach has been further validated on a dual-core FPGA prototype running applications with full SMP Linux, where we have demonstrated speedups of 2.35x and 2.27x over software-based prefetching and decoupling, respectively. Lastly, this approach has been taped out in silicon as part of a manycore chip design.